Hvordan estimerer vi restlevetid på tværs af bygningsdele, materialer og bygningstyper? Her får du den korte forklaring på, hvordan vores levetidsmodel fungerer, hvad der gør den unik, og hvilke forbedringer vi arbejder på.
Hvad modellen gør
Vores levetidsmodel er en boosted decision tree model (CatBoost), der estimerer resterende levetid for alle registrerede bygningsdele.
Den trækker på 40 forskellige inputfaktorer, blandt andet:
- bygningens anvendelse og alder
- kvadratmeter
- energimærke og opvarmningstype
- befolkningstæthed
- materiale og mængde for hver bygningsdel
- eventuelle energiforbedringer
Fra levetid til tilstandsscore
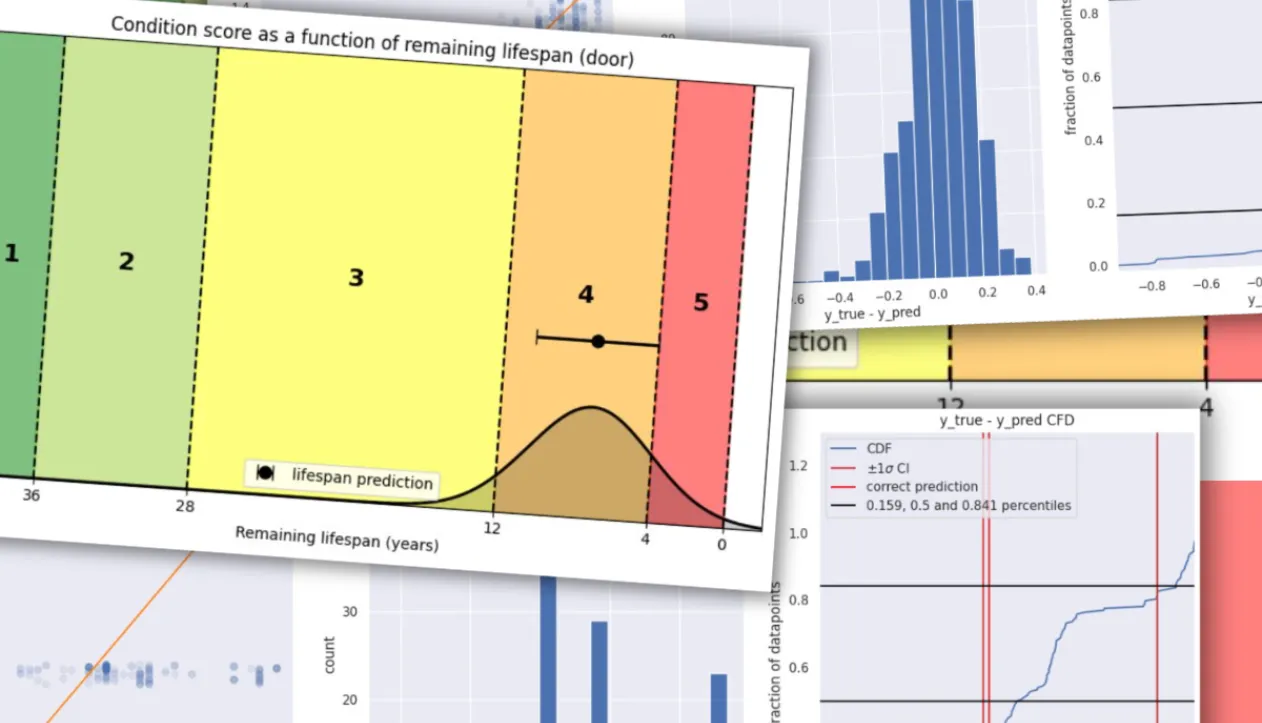
Når modellen har beregnet den resterende levetid, omsættes resultatet til en tilstandsscore fra 1 til 5. Det sker ved at sammenligne model-estimatet med referenceværdier fra BUILD’s levetidstabeller.
Et eksempel: En dør med en total levetid på 40 år får:
- Score 1: mere end 36 år tilbage
- Score 2: 36–28 år
- Score 3: 28–12 år
- Score 4: 12–4 år
- Score 5: mindre end 4 år tilbage
Det kan give sjove grænsetilfælde. En 15 år gammel dør kan stadig få tilstand 1, hvis modellen vurderer, at den har mere end 36 år tilbage. Men det er netop pointen.
Modellen lærer af reelle observationer, hvor mange bygningsdele holder længere end tabellerne tilsiger.
Sikkerhed: hvor sikre er vi på estimatet
Når modellen vurderer restlevetiden for en bygningsdel, beregner den samtidig en usikkerhed på estimatet. Man kan tænke på det som et mål for, hvor stor varians der er i forudsigelserne for en bygningsdel. En lille usikkerhed kommer af, at forudsigelserne generelt rammer rigtigt for en given bygningsdel og restlevetid.
Den sikkerhedsscore der beregnes, er sandsynligheden for at standen på bygningsdelen er estimeret korrekt.
Et eksempel: Hvis modellen vurderer, at en dør er i stand fire, med en sikkerhed på 77 procent, kan det forventes at være korrekt i 77 procent af tilfældene. Der er altså en hvis sandsynlighed, for at døren rent faktisk er i stand tre eller stand fem.
Ved at vise sikkerhedsscore giver vi ikke blot et estimat på stand og restlevetid, men vurderer også hvad sandsynligheden er, for at estimatet er korrekt. Det gør resultaterne mere gennemsigtige og brugbare i praksis, når der skal træffes beslutninger på baggrund af data.
Hvorfor ikke bare to modeller
Tidligere brugte vi én model til levetid og en anden til tilstand. Det gav uoverensstemmelser, for eksempel når levetidsmodellen vurderede en lang restlevetid, mens tilstandsmodellen vurderede dårlig stand.
Nu lader vi levetiden styre tilstanden, så estimaterne altid hænger sammen. Til gengæld kræver det, at oversættelsen bliver mere intelligent, og det er præcis det, vi arbejder på.
Lavthængende forbedringer vi arbejder på
Alderskorrektion af score
Nye bygningsdele bør ikke lande i tilstand 2 eller 3, og meget gamle bør ikke blive i tilstand 1, selv hvis levetidsestimatet er højt.
Datadrevet beregning af sikkerhed
I stedet for at antage en normalfordeling lader vi den faktiske datafordeling bestemme, hvordan sikkerheden beregnes.
Hvorfor det her er værdifuldt
Fordi modellen bygger på virkelige observationer fra mange ejendomsporteføljer, afspejler den virkeligheden bedre end teoretiske tabeller.
Resultatet er:
- Mere planlagt vedligehold
- Færre fejlinvesteringer
- Lavere teknisk gæld
- Et mere realistisk datagrundlag for beslutninger
Vil du se, hvordan dine bygninger klarer sig?


Tilmeld dig vores nyhedsbrev
Få indblik i nye funktioner, kundecases og nyheder fra proprty.ai – direkte i din indbakke.
%202.webp)
